フリーウエア利用5 MeCab
1)概要
MeCabは、文章を形態素(意味をもつ最小の単位)に分解するオープンソースの「形態素解析エンジン」です。MeCabはフリーソフトウエアで、京都大学情報学研究科、日本電信電話株式会社コミュニケーション科学基礎研究所の共同研究で開発されたもので、開発者は工藤拓氏です。有用なソフトの公開に感謝します。
C言語のインターフェースが公開されていますので、Embarcadero C++ Compiler で利用する場合の手順、プログラムの組み方を紹介します。
2)ソフトの入手方法、
公式のホームページ(http://taku910.github.io/mecab/)からWindows版のパッケージをダウンロードしてインストールができます。
MeCabの解説・インストールは、こちらが参考になりました。
後で出てきますが、オプションについては、こちらが詳しい。
インストーラに従ってインストールした場合に、解凍される次のファイルを使用します。(環境やインストール方法によってフォルダが異なる場合があります)
「C:\Program Files (x86)\MeCab\sdk\」:「example.c」(サンプルプログラム)、「mecab.h」(ヘッダファイル)
「C:\Program Files (x86)\MeCab\bin\」:「libmecab.dll」(dll)
3)ライブラリの作成法
コマンドライン・ツールのimplib.exeを使って、上記のlibmecab.dllからライブラリ(libmecab.lib)を作成します。実行結果は以下の①です。
ここで使用したソースプログラム、実行プログラムはこちらです。(ヘッダー、dll、ライブラリはご自分で取得してください)
<①実行結果>
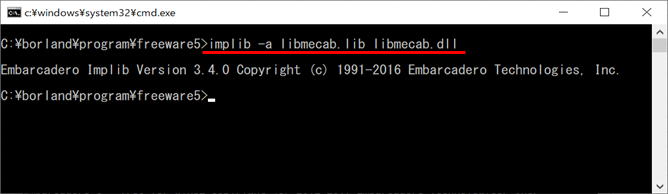
MeCabで公開されている、上記のサンプルプログラムをEmbarcadero C++ コンパイラで.EXEファイル
に変換します。このC言語のサンプルは、シングルスレッド環境用です。
変更箇所は、ソースプログラムに記載しました。いくつか、コメントを追加しています。
コンパイル結果は②です。
<②コンパイル結果>
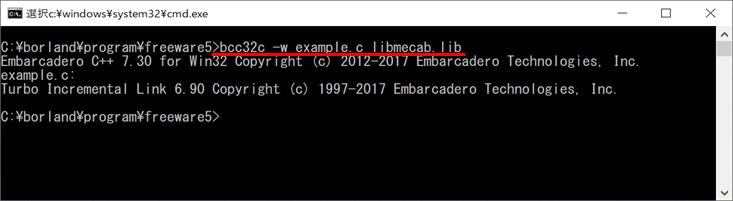
ソースプログラムが③ですが、実行結果やプログラムの意味をいくつかに分けて説明します。
<③ソースプログラム>
//#include <mecab.h>
#include <stdio.h>
// 位置を変更 2023.10.11 K.N
#include "mecab.h"
#define CHECK(eval) if (! eval) { \
fprintf (stderr, "Exception:%s\n", mecab_strerror (mecab)); \
mecab_destroy(mecab); \
return -1; }
int main (int argc, char **argv) {
char input[] = "太郎は次郎が持っている本を花子に渡した。";
mecab_t *mecab;
const mecab_node_t *node;
const char *result;
int i;
// size_t len; // 使っていない。2023.10.11 K.N
// ---- 1:設定、ハンドル作成 -----
// Create tagger object
mecab = mecab_new(argc, argv);
CHECK(mecab);
// ---- 2:形態素に分解 -----
// Gets tagged result in string.
result = mecab_sparse_tostr(mecab, input);
CHECK(result)
printf ("INPUT: %s\n", input);
printf ("RESULT:\n%s", result);
// ---- 3:形態素に分解、NBEST、一括
// Gets N best results
result = mecab_nbest_sparse_tostr (mecab, 3, input);
CHECK(result);
fprintf (stdout, "NBEST:\n%s", result);
// ---- 4:形態素に分解、NBEST、順次
CHECK(mecab_nbest_init(mecab, input));
for (i = 0; i < 3; ++i) {
printf ("%d:\n%s", i, mecab_nbest_next_tostr (mecab));
}
// ---- 5:形態素分解、形態素ごとに表示
// Gets node object
node = mecab_sparse_tonode(mecab, input);
CHECK(node);
for (; node; node = node->next) {
if (node->stat == MECAB_NOR_NODE || node->stat == MECAB_UNK_NODE) {
fwrite (node->surface, sizeof(char), node->length, stdout);
printf("\t%s\n", node->feature);
}
}
// ---- 6:辞書情報の表示
// Dictionary info
const mecab_dictionary_info_t *d = mecab_dictionary_info(mecab);
for (; d; d = d->next) {
printf("filename: %s\n", d->filename);
printf("charset: %s\n", d->charset);
printf("size: %d\n", d->size);
printf("type: %d\n", d->type);
printf("lsize: %d\n", d->lsize);
printf("rsize: %d\n", d->rsize);
printf("version: %d\n", d->version);
}
mecab_destroy(mecab);
return 0;
}
mecab_new(argc, argv)関数で、ハンドルを作成します。ここでは、指定しませんが、パラメータを指定できます。パラメータは、下の一覧を参照してください。
■ ハンドルの作成
【関数1】mecab_t* mecab_new(int argc, char **argv);
【関数2】mecab_t* mecab_new2(const char *arg);
・機能・・・MeCabにアクセスする「ハンドル(mecab_t*)」を作成する。
・引数1・・・オプションを「int argc, char **argv」の形式で指定する。
・引数2・・・オプションを「const char *arg」の形式で指定する。
・戻り値・・mecab_t* が返る。
・元の関数(C++)
1、MeCab::Tagger::create(argc, argv)
2、MeCab::Tagger::create(arg) |
■パラメータ一覧
sage: mecab [options] files
-r, --rcfile=FILE リソースファイルを指定
-d, --dicdir=DIR システム辞書の保管ディレクトリ
-u, --userdic=FILE ユーザ辞書ファイル名を指定
-l, --lattice-level=INT lattice information level (DEPRECATED)
-D, --dictionary-info 辞書情報の表示
-O, --output-format-type=TYPE 出力フォーマットの指定(wakati,none,...)
-a, --all-morphs 全morphsの出力 (デフォルト:no)
-N, --nbest=INT N best数の指定(デフォルト:1)
-p, --partial partial parsing mode (デフォルト:no)
-m, --marginal output marginal probability (デフォルト:no)
-M, --max-grouping-size=INT 未知語の最大グルーピングサイズ (デフォルト:24)
-F, --node-format=STR 辞書に定義ありの指定
-U, --unk-format=STR 未知語(unknown)の指定
-B, --bos-format=STR 文の始まり(BOS)の指定
-E, --eos-format=STR 文の終わり(EOS)の指定
-S, --eon-format=STR NBESTの終わり(EON)の指定
-x, --unk-feature=STR 未知語の文字の指定
-b, --input-buffer-size=INT 入力バッファーサイズ (デフォルト:8192)
-P, --dump-config MeCab パラメータの表示
-C, --allocate-sentence 入力のためにメモリの再割り当て
-t, --theta=FLOAT set temparature parameter theta (デフォルト:0.75)
-c, --cost-factor=INT set cost factor (デフォルト:700)
-o, --output=FILE 出力ファイル名
-v, --version バージョンの表示
-h, --help ヘルプファイルの表示
|
mecab_sparse_tostr(mecab, input)関数で、文字列を与えて形態素に分解します、結果は④です。
<④実行結果>
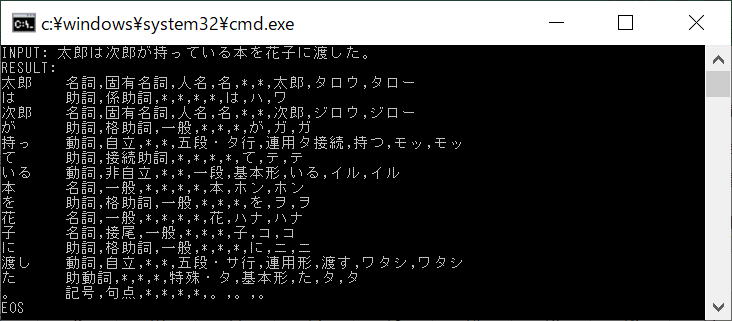
■形態素、分解
【関数1】 const char* mecab_sparse_tostr(mecab_t *mecab, const char *str);
【関数2】 const char* mecab_sparse_tostr2(mecab_t *mecab, const char *str, size_t len);
【関数3】 char* mecab_sparse_tostr3(mecab_t *mecab, const char *str, size_t
len,
char *ostr, size_t olen);
・機能・・・・形態素に分解する。(最適なもの)
・引数1・・・ハンドル、分解する文字列
・引数2・・・ハンドル、分解する文字列、文字列長
・引数3・・・ハンドル、分解する文字列・文字列長、結果を入れる文字列・文字列長
・戻り値・・・結果が返る。
・元の関数(C++)
1、MeCab::Tagger::parse(const char *str)
2、MeCab::Tagger::parse(const char *str, size_t len)
3、MeCab::Tagger::parse(const char *str, char *ostr, size_t olen)
|
mecab_nbest_sparse_tostr()関数で、形態素に分解し、上位の3件を表示します、結果は⑤です。
表示する件数は関数の引数で指定します。
<⑤実行結果>
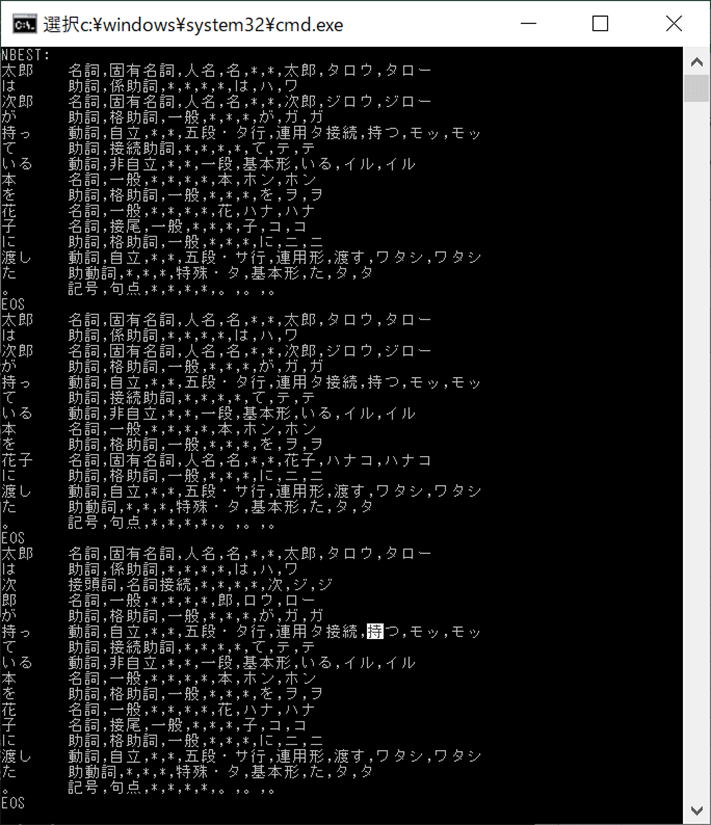
■形態素、分解・NBEST
【関数1】 const char* mecab_nbest_sparse_tostr(mecab_t *mecab, size_t N,
const char *str);
【関数2】 const char* mecab_nbest_sparse_tostr2(mecab_t *mecab, size_t N,
const char *str, size_t len);
【関数3】 char* mecab_nbest_sparse_tostr3(mecab_t *mecab, size_t N,
const char *str, size_t len,
char *ostr, size_t olen);
・機能・・・・形態素で分解し、最適なものから順に、指定された数だけ出力する。
・引数1・・・ハンドル、作成する個数、分解する文字列
・引数2・・・ハンドル、作成する個数、分解する文字列・文字列長
・引数3・・・ハンドル、作成する個数、分解する文字列・文字列長、結果を入れる文字列・文字列長
・戻り値・・・結果が返る。
・元の関数(C++)
1、MeCab::Tagger::parseNBest(size_t N, const char *str)
2、MeCab::Tagger::parseNBest(size_t N, const char *str, size_t len)
3、MeCab::Tagger::parseNBest(size_t N, const char *str, char *ostr, size_t olen)
|
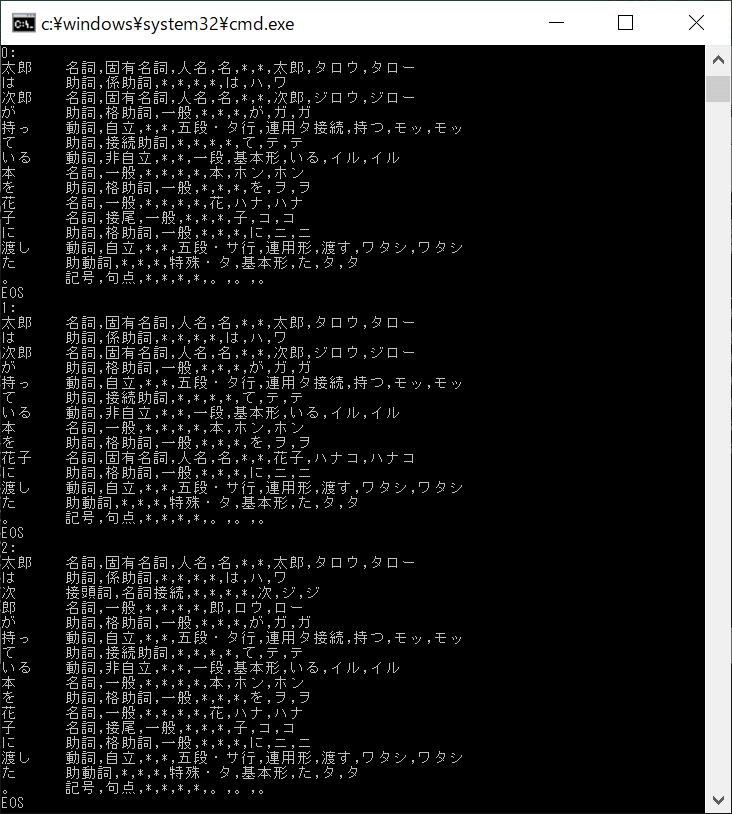
mecab_nbest_init()で、分解する文字列を指定し、mecab_nbest_next_tostr()で順次取得できるので、必要なだけ繰り返します。実行結果が⑥です。
<⑥実行結果>
■初期化
【関数1】 int mecab_nbest_init(mecab_t *mecab, const char *str);
【関数2】 int mecab_nbest_init2(mecab_t *mecab, const char *str, size_t len);
・機能・・・・NBESTで、形態素の分解する場合に初期化する。
・引数1・・・ハンドル、分解する文字列
・引数2・・・ハンドル、分解する文字列・文字列長
・戻り値・・・?
・元の関数(C++)
1、MeCab::Tagger::parseNBestInit(const char *str)
2、MeCab::Tagger::parseNBestInit(const char *str, size_t len) |
■順次表示
【関数3】 const char* mecab_nbest_next_tostr(mecab_t *mecab);
【関数4】 char* mecab_nbest_next_tostr2(mecab_t *mecab, char *ostr, size_t olen);
・機能・・・・次の形態素分解を表示する。
・引数3・・・ハンドル
・引数4・・・ハンドル、出力文字列・文字列長
・戻り値・・・結果を返す。
・元の関数(C++)
3、MeCab::Tagger::next()
4、MeCab::Tagger::next(char *ostr, size_t olen)
|
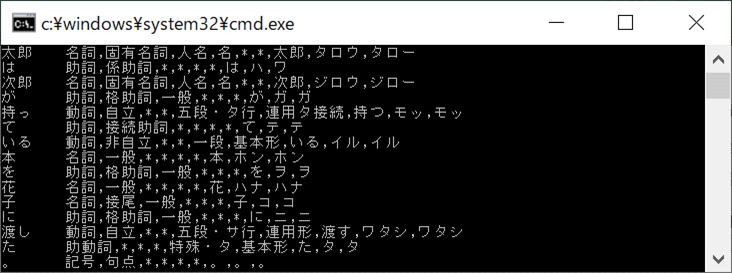
mecab_sparse_tonode()で、分解する文字列を指定すると、ノード(Node、mecab_node_t *:文字列を分かち書きを追えるように分解)が返ります。プログラムで、順に取り出します。実行結果が⑦です。
Nodeの構造は、下記に記しますが、statで要素の内容を判断し、指定された次の要素に進みます。次の要素が指定されてければ終了となります。
<⑦実行結果>
■形態素に分解・分かち書き
【関数1】const mecab_node_t* mecab_sparse_tonode(mecab_t *mecab, const char*);
【関数2】const mecab_node_t* mecab_sparse_tonode2(mecab_t *mecab, const char*, size_t);
・機能・・・・形態素で分解し、分かち書きできるnodeの形で返す。(最適なもの)
・引数1・・・ハンドル、分解する文字列
・引数2・・・ハンドル、分解する文字列・文字列長
・戻り値・・・結果が返る。
・元の関数(C++)
1、MeCab::Tagger::parseToNode(const char *str)
2、MeCab::Tagger::parseToNode(const char *str, size_t len)
|
■構造体 ノード
struct mecab_node_t {
struct mecab_node_t *prev; // 前ノード
struct mecab_node_t *next; // 次ノード
struct mecab_node_t *enext; // node which ends at the same position
struct mecab_node_t *bnext; //node which starts at the same position
struct mecab_path_t *rpath; // 右path (NULL: MECAB_ONE_BEST mode)
struct mecab_path_t *lpath; // 左path (NULL: MECAB_ONE_BEST mode)
const char *surface; //surface string
const char *feature; //feature string
unsigned int id; // unique node id
unsigned short length; //length of the surface form
unsigned short rlength; // 変換前の文字数
unsigned short rcAttr; // right attribute id
unsigned short lcAttr; // left attribute id
unsigned short posid; // unique part of speech id
unsigned char char_type; // 文字コード
unsigned char stat; // ステータス(MECAB_NOR_NODE, MECAB_UNK_NODE, MECAB_BOS_NODE, MECAB_EOS_NODE, or MECAB_EON_NODE)
unsigned char isbest; //set 1 if this node is best node
float alpha; //available when MECAB_MARGINAL_PROB
float beta; //available when MECAB_MARGINAL_PROB
float prob; //available when MECAB_MARGINAL_PROB
short wcost; //word cost
long cost; //best accumulative cost
|
■定数 Node::stat
MECAB_NOR_NODE = 0, // 辞書に定義済み
MECAB_UNK_NODE = 1, // 辞書に未定義
MECAB_BOS_NODE = 2, // 文の最初
MECAB_EOS_NODE = 3, // 文の終わり
MECAB_EON_NODE = 4 // Nodeの終わり |
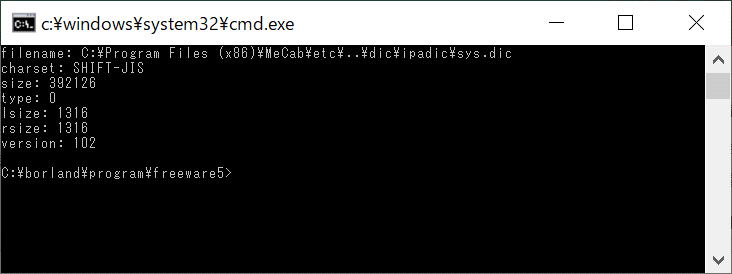
mecab_dictionary_info()で辞書情報を取得する。辞書情報の構造体は、下記です。
辞書は複数ある場合もあるので、順に取得できる。実行結果が⑧です。
<⑧実行結果>
■辞書情報の表示
【関数】const mecab_dictionary_info_t* mecab_dictionary_info(mecab_t *mecab);
・機能・・・・辞書情報(mecab_dictionary_info_t *)を取得する。
・引数・・・・ハンドル
・戻り値・・・辞書情報の結果を返す。
・元の関数(C++)
MeCab::Tagger::dictionary_info()
|
■構造体 辞書情報
struct mecab_dictionary_info_t {
const char *filename; // 辞書名
const char *charset; // 文字コード
unsigned int size; // 登録語数
int type; // 辞書タイプ(MECAB_USR_DIC, MECAB_SYS_DIC, or MECAB_UNK_DIC
unsigned int lsize; // left attributes size
unsigned int rsize; // right attributes size
unsigned short version; // バージョン
struct mecab_dictionary_info_t *next; // 次の辞書
}; |
|