 「超漢字あれこれ」へ戻る
「超漢字あれこれ」へ戻る
異体字のことなど
最近、漢字の異体字とこれに関連して文字コードのことをちょいと考える機会があったもので
すから、徒然なるままに。
《字形の概念》
コンピュータの文字コードは、ある漢字の字形の「概念」を伝えるものであり、字形そのものを
規定するものではない。したがって、ユニコードの考え方はそれでよいのだ。という説があるよ
うで、一見説得力があるのですが、私には単なる机上の空論、あるいは後から取って付けたユニ
コード擁護論の匂いがします。ま、単なる感想ですが。
それにしても、個々の漢字について世界共通の字形「概念」なるものが存在し得るのでしょうか?
無理な話だと思うんですがねえ。文字は自然科学的事象ではありません。個人、地域、民族、そ
して歴史などの様々な要素が絡み合っています。並の人間って、そんなに物分かりの良い優等生
ではなく、エゴ、気配り、その場の思いつきなどなどによってフラフラするんであって、論理的
に動くような代物ではないのは、自明のことでしょう。
コンピュータ上での個々の漢字の字形について、みなが共通の「概念」を持つなんて、“幼年期”
にある“地球”人には見果てぬ夢でしょう。
一切の圧力や駆け引きなくそれが実現したら、その時“地球”は“幼年期”を脱したのです。
《コンピュータで異体字や旧字体は必要か?》
現代人の日常生活で、という限定付きなら、異体字も旧字体も要らないし、新字体で十分。と言っ
たら、人名・地名を考えたらそんなことは言えん、というクレームがすぐつくでしょう。事程左様
に漢字の扱いは難しい、と言えましょうか。これが、コンピュータ上で日本や中国の古典文献を扱
うとなると、どうなるか。異体字や旧字体はいやでも必要になるのです。
新字体でも旧字体でも、意味が通じて読めりゃいいじゃないか、という考え方があります。その通
りで、単に新たに文章を書くなら、自分で使う字体を決めてそれのみを使えばよいのです。それが
新字体であろうと旧字体であろうと構わないし、異体字も必要ない。古典文献を電子テキスト化す
る場合でも、これで押し通すことは可能です。現に中国では簡体字で電算印刷された古典が沢山出
ています。読み物としてならこれでよいのです。「あまり」の意なのに「餘」ではなくて、「我」
の意の「余」と書いてあっても分かります。「辯護」人が、冠をかぶった「弁護」人になっていた
としても笑って許せます(因みに中国簡体字は「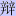
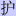 」)。
」)。
しかし、現にある古写本や古版本を電子テキストに置き換えたり、数種類のエディションを参照し
て電子テキスト版校定本を作る場合は、そうはいきません。何故なら、「校勘記」が書けないから
です。異体字を使わないで「校勘記」が書けるわけがありませんし、「校勘記」のないテキストは
古典籍としては信頼できません(あっても信頼できないこともありますが)。
たとえば、昔、先師について敦煌で発見された「変文」などの俗文学の写本を、マイクロフィルム
の焼き付けを頼りに読んだのですが、敦煌文書は俗字、異体字の宝庫です。日本の古写本の字体と
共通するものも多いのですが、そうでないものも多い。それを超漢字で電子テキスト化できたらな
あ、と常々思っています。“見果てぬ夢”かなあ。
《TRONコード》
TRONコードは、今ある種々の文字コードを単にそのまま飲み込んだもので、同一文字の重複を許し
ています。世界がユニコードに一元化されるとはとても思えませんから、異体字同一視検索ができれ
ばその方が実際的だろう、くらいにこれまでは思っていました。ところが、先月、「Interface」の
昨年12月号にPMCの松為彰さんが書いた「多漢字問題とTRONコード」という論文のコピーをいただ
いて、TRONコードが今のような形になったのにはそれなりにちゃんとした主張があったのだと知り
ました。うむ、認識不足でした。興味のある方は「Interface」のバックナンバーをお読みください。