信号解析 第9回講義録
日時:2006年6月26日
講義内容:ARモデルの推定
担当者:情報知能工学科 小島史男
1. はじめに
今回よりこの講義の最終段階にはいります。いままで信号の統計処理方法および統計モデルについて学習してきました。今回からはモデルを使って信号を“読む”ことをおこないましょう。ARMAモデルのなかでもARモデルは取り扱いが比較的容易です。本日の講義では時系列信号をARモデルに当てはめる計算法について説明します。
2. ARモデルの復習
ARモデルはARMAモデルの特別の場合で、ガウス型白色雑音系列![]() を用いて
を用いて
![]()
で与えられることはすでに学習しました。![]() は平均
は平均![]() 分散
分散![]() の正規分布に従う白色雑音で、時系列の過去の信号
の正規分布に従う白色雑音で、時系列の過去の信号![]() とは独立と仮定していました。今回の目的は任意の時系列信号
とは独立と仮定していました。今回の目的は任意の時系列信号![]() が与えられたとき、このデータをARモデルによって当てはめを行おうということです。そのためにするべきことは何でしょうか? まずARモデルの次元
が与えられたとき、このデータをARモデルによって当てはめを行おうということです。そのためにするべきことは何でしょうか? まずARモデルの次元![]() を決めなければなりません。これは赤池法でAICの値を求めれば良いことになります。適当な次元がわかれば、あと決めるべきことはARモデルの
を決めなければなりません。これは赤池法でAICの値を求めれば良いことになります。適当な次元がわかれば、あと決めるべきことはARモデルの![]() 次元の係数ベクトル
次元の係数ベクトル![]() を推定することになります。もちろん白色雑音の分散
を推定することになります。もちろん白色雑音の分散![]() も推定する必要があります。ARモデルではこの一連の作業が非常に見通しよくできるのです。
も推定する必要があります。ARモデルではこの一連の作業が非常に見通しよくできるのです。
3. ARモデルの尤度関数
ではまずARモデルの統計的性質を調べてみましょう。次数![]() のときの時系列
のときの時系列![]() の各要素の平均値
の各要素の平均値![]() は
は![]() また自己共分散関数
また自己共分散関数![]() は
は

であたえられることは第7回の講義で学習しました。このことからARモデルの尤度関数をもとめていきましょう。このモデルは線形であり、かつ入力![]() はガウス型確率密度関数に従います。このことはその出力である
はガウス型確率密度関数に従います。このことはその出力である![]() もガウス型となることを意味します。入力時系列信号
もガウス型となることを意味します。入力時系列信号![]() の統計モデルは白色雑音が完全に独立な時系列であるので、その確率密度関数は
の統計モデルは白色雑音が完全に独立な時系列であるので、その確率密度関数は
![]()
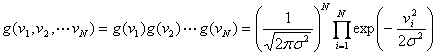
のように直積で書くことができます。しかし、出力時系列信号![]() はどうでしょうか。この分布はガウス分布にはちがいがありませんが、それぞれは独立ではありません。この場合
はどうでしょうか。この分布はガウス分布にはちがいがありませんが、それぞれは独立ではありません。この場合![]() 次のガウス型確率密度関数が統計モデルとなります。すなわち
次のガウス型確率密度関数が統計モデルとなります。すなわち

で与えられます。推定すべきは![]() の
の![]() 次元のパラメータベクトルです。したがってその赤池情報量基準は
次元のパラメータベクトルです。したがってその赤池情報量基準は
![]()
で与えられます。復習になりますが、適当な最大次元![]() までのARモデルのAICを計算し、そのなかで最小値となる次数を最適な次数
までのARモデルのAICを計算し、そのなかで最小値となる次数を最適な次数![]() を決定できることになります。上の式の第1項は最大対数尤度関数であり、
を決定できることになります。上の式の第1項は最大対数尤度関数であり、![]() はそれぞれに次元において最大尤度となる最適パラメータを意味します。このパラメータの決定方法について以下考察をすすめましょう。
はそれぞれに次元において最大尤度となる最適パラメータを意味します。このパラメータの決定方法について以下考察をすすめましょう。
4.ユールウオーカーの方法
第7回の講義で説明しましたが、![]() 次のARモデルの自己共分散関数はユールウオーカーの方程式で与えられます。ところで時系列信号
次のARモデルの自己共分散関数はユールウオーカーの方程式で与えられます。ところで時系列信号![]() から標本自己共分散関数が
から標本自己共分散関数が
![]()
で計算できることを2回目の講義で学習しました。もしこれが自己共分散の十分良い近似となっているならば、さきほどのユールウオーカーの方程式にこれを代入して

を得ることができます。2番目の式はよく見るとAR係数![]() を未知数とする以下の連立方程式に帰着されます。
を未知数とする以下の連立方程式に帰着されます。
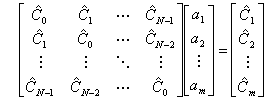
この方程式を解けば容易にAR係数を求めることができます。また1番目の式に求めた定値を代入すると入力であるガウス型白色雑音の分散の推定値
![]()
も同時に計算できることになります。こうして求めたパラメータのことをユールウオーカーの推定値と呼びます。ところで![]() をさきほどの対数尤度関数に代入したときにはたして最大値をとるのでしょうか。これは以下のようにして確認することができます。つまり、ARモデルによる予測誤差分散は
をさきほどの対数尤度関数に代入したときにはたして最大値をとるのでしょうか。これは以下のようにして確認することができます。つまり、ARモデルによる予測誤差分散は
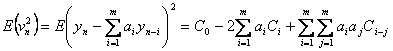
となります。そこで係数パラメータで偏微分し停留点は
![]()
を満足するはずです。つまり共分散関数![]() にその標本共分散
にその標本共分散![]() を代入して、先ほどの連立方程式を求めること自体が予測誤差分散を近似的に最小にしていることになるわけです。
を代入して、先ほどの連立方程式を求めること自体が予測誤差分散を近似的に最小にしていることになるわけです。
4.レビンソンのアルゴリズム
さて以上の手順をまとめるとm=1からm=Mまでの次数ごとに、連立方程式を解くことでAICを求め、最適な次数決定とパラメータ![]() を決めればよいことになりますが、次数が大きくなるにつれて方程式をいちいち求めていくのはめんどうです。レビンソンのアルゴリズム(Levinson’s Algorithm)ではこれまでの計算を逐次的に効率的に解く方法です。このアルゴリズムを最後に示します。
を決めればよいことになりますが、次数が大きくなるにつれて方程式をいちいち求めていくのはめんどうです。レビンソンのアルゴリズム(Levinson’s Algorithm)ではこれまでの計算を逐次的に効率的に解く方法です。このアルゴリズムを最後に示します。
Step 1: 初期値の設定をおこなう。
![]()
Step 2: AR次数![]() について下記の反復演算をおこなう。
について下記の反復演算をおこなう。
(2.1) 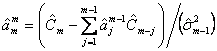
(2.2) ![]()
(2.3) ![]()
(2.4) ![]()
上記のアルゴリズムでのAR係数![]() はAR次数が
はAR次数が![]() のときの
のときの![]() 番目のAR係数の推定値を意味しています。
番目のAR係数の推定値を意味しています。
本日の宿題:レビンソンのアルゴリズムを作ってみましょう。適当な次元のARモデルで求めたデータを![]() として標本自己共分散の系列をだしてみてください。そのあとレビンソンのアルゴリスムで計算して求めた推定値およびAIC値はもとの疑似データの結果と較べてみてください。すこし時間がかかるかもしれませんがチャレンジしてみてください。問題に使うデータ(rawData.lzh)はダウンロードして使ってください。なおプログラム例は来週アップいたします。
として標本自己共分散の系列をだしてみてください。そのあとレビンソンのアルゴリスムで計算して求めた推定値およびAIC値はもとの疑似データの結果と較べてみてください。すこし時間がかかるかもしれませんがチャレンジしてみてください。問題に使うデータ(rawData.lzh)はダウンロードして使ってください。なおプログラム例は来週アップいたします。
これまでのプログラムの修正について:第6回、第8回にアップしたプログラム修正いたしましたので、再度ダウンロードしてください。メモリーリークはなくなりました。